02 · Article
On this page21 sections
- The real bottleneck was trust
- The setup was simple and strict
- Operations mattered more than model quality
- What evidence looked like in practice
- The results were the point
- What changed in my workflow
- Why this matters if you build with agents
- A minimal checklist if you want to try this
- The bigger takeaway
- The cost of coordination
- The scope rules that keep it sane
- Where I use this approach now
- What I would automate next
- What I would improve next
- The template I keep reusing
- The governance layer
- How I document the run
- The cost of trust (and why it is worth it)
- Related Guides
- Related Stories
- Learn More
There is a moment in every automation sprint when speed stops mattering. You are not chasing throughput. You are chasing trust.
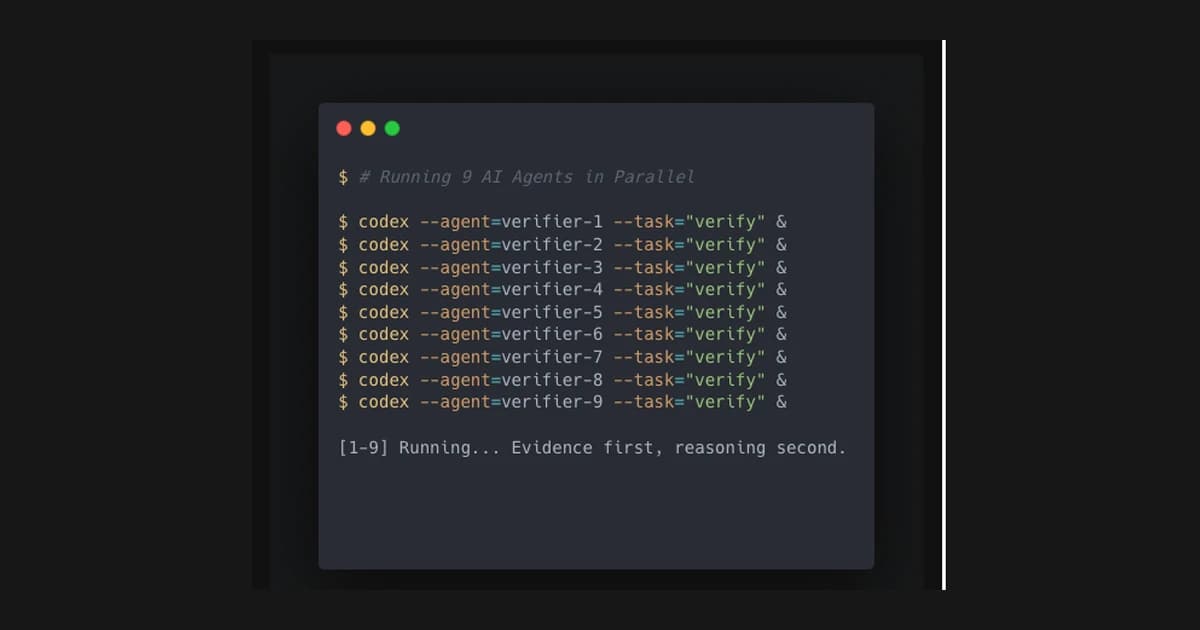
That was the point of this experiment. I ran nine Codex CLI agents at once, not for speed — Codex is deliberately slow and thorough — but to verify claims made by earlier agents. The work was not glamorous. It was a cross-checking run with receipts.
Parallel agents are a superpower, but only if you can reconcile what they say. Otherwise you are just multiplying the noise.
The real bottleneck was trust
I had a list of claims that were already "done." That is usually the most dangerous moment. It feels safe to move on, but that is when sloppy assumptions sneak in.
A single model verifying its own work is not verification. It is self-reporting. So the premise was simple: separate the verifier from the original work and force evidence on every claim.
That meant changing the goal. The goal was not to get answers. The goal was to get proof that the answers were real.
The setup was simple and strict
I split the claim list into nine piles and assigned one agent per pile. Every agent got the same rubric and the same constraints.
The rubric had three rules:
- Show the concrete evidence (commands, logs, citations).
- Stop once a claim is verified or blocked.
- If you cannot verify, say so and move on.
I did not want debate. I wanted proof.
It is tempting to let agents do the reasoning and leave the evidence for later. This run inverted that. Evidence first, reasoning second. If there was no evidence, the claim did not count.
Operations mattered more than model quality
The hardest part was not the prompts. It was the ops. Each agent had a 30-minute timeout. Approvals had to stay active. Workloads had to be small enough to finish cleanly.
I learned fast that runtime controls are part of the system, not an afterthought. One flag changed everything: pty: true. That removed the brittle timeout behavior and made long verification chains possible.
If you do not get the runtime right, your model is irrelevant. You will only see half-finished runs and missing proof.
What evidence looked like in practice
I defined evidence as artifacts a human could re-check: a git diff, a file on disk, a deployment log, or a command output. If an agent could not point to an artifact, the claim stayed unverified. That rule felt strict, but it removed ambiguity and kept the system honest.
The results were the point
The run verified 16 out of 16 claims. It also flagged three discrepancies for follow-up.
Those three discrepancies were the real win. They were the places where earlier assumptions drifted away from reality. Without independent checks, those would have gone into production as truth.
This is the value of parallel verification. It does not just confirm what is right. It reveals what is wrong.
What changed in my workflow
I now design multi-agent runs around verification first. The output I want is not a perfect summary. It is a trail of evidence that I can audit later.
That shift is subtle but powerful. It changes how you split tasks, how you assign responsibilities, and how you measure success.
A few practical rules I am keeping:
- Every claim must have a proof artifact.
- If the proof is weak, the claim is unverified.
- Parallelism only helps if you can reconcile outputs.
It sounds obvious, but it is easy to forget when you are chasing speed. I would rather be slower with receipts than fast with guesses.
Why this matters if you build with agents
Multi-agent systems are not just about throughput. They are about reliability. If you are using them in production workflows, you are taking on a new kind of operational debt.
You need to decide where the truth lives. Is it in the agent's summary? In a log? In a database? In a command output?
My current answer is: the truth lives in the artifacts. The agent is just the courier.
That framing makes it easier to handle disagreements. It also makes it easier to explain your system to someone else. You are not asking them to trust a model. You are showing them the paper trail.
A minimal checklist if you want to try this
Start with two or three agents and keep it boring:
- Split the claim list into small chunks
- Give every agent the same rubric
- Require artifacts as proof
- Stop when a claim cannot be verified
- Review artifacts, not summaries
The bigger takeaway
Parallel agents are powerful, but they only earn their keep when they improve confidence. If you cannot verify, you do not have a system. You have a chorus.
The experiment worked because it forced me to design for verification. The tooling was the enabler, not the hero. The real hero was the boring discipline of checking.
If you are building with agents, start there. Decide what proof looks like. Make that the primary output. Then scale the number of agents.
That order matters.
The cost of coordination
The hidden cost of multi‑agent systems is coordination. Every additional agent adds overhead: more prompts, more reviews, more artifacts. The only way it stays worth it is if the coordination cost is lower than the time saved.
That is why I keep the system narrow. If a task cannot be verified quickly, I reduce the scope until it can. This keeps the system efficient without sacrificing trust.
The scope rules that keep it sane
I use three rules for scope:
- If a task cannot be verified in under 10 minutes, it is too big.
- If a task needs more than one approval window, it should be split.
- If a task touches customers, it needs a human checkpoint.
These rules prevent the system from drifting into vague work. They also reduce the rate of failed runs.
Where I use this approach now
The verification workflow is now my default for:
- client proposals and audits
- code changes that touch revenue or legal surfaces
- deployments that cannot be easily rolled back
These are the places where trust matters more than speed.
What I would automate next
The next step is to formalize the evidence layer: a structured store of diffs, commands, and outcomes that can be searched later. When that exists, the audit trail becomes a first‑class asset, not just a side effect.
What I would improve next
The next improvement is not another model. It is better observability. I want a small dashboard that shows which agents ran, which artifacts they produced, and what is still unverified. That makes review faster and reduces context switching.
The template I keep reusing
Every run starts with the same template:
- context (what matters)
- task list (ordered)
- constraints (what to avoid)
- verification (what proves success)
The template keeps the work consistent and makes the outputs easier to compare.
Have you tried parallel agents in real workflows yet? What broke first?
The governance layer
The bigger the system gets, the more you need governance. That means explicit boundaries:
- which tasks can run unattended
- which tasks always require human approval
- which outputs are considered “publishable”
Without governance, you end up with speed but no reliability. With it, you can move fast and still trust the result.
How I document the run
Every multi‑agent session gets a short log:
- what the task was
- which agents ran
- what artifacts were produced
- what remained unverified
This is not busywork. It is what lets you audit later without re‑running the whole workflow.
The cost of trust (and why it is worth it)
Verification is slower than blind execution, but the cost is worth paying. The alternative is quietly shipping mistakes that look right but are wrong. I would rather spend extra time verifying than fix damage later.
That is the real lesson from this experiment: the compounding value is not speed. It is confidence.
Related Guides
- AI Agents Setup Guide — Patterns, stacks, and guardrails
- AI Agents for Solo Founders — Build a 24/7 team
- Overnight AI Builds Guide — Safe overnight automation
Related Stories
- Running 15 AI Agents Daily — The full architecture
- How I Built 14 AI Agents — From one agent to a team
Learn More
For the complete agent system, join the AI Product Building Course.